
Welcome back to the Lab! I assume you’ve read Part 1, the debut of Dr. Frankendata and you’re ready for a second dose of my mad data sciencing. Today, we delve into my go-to best practices for CRM and email marketing data investigations. While the examples below are specific to Salesforce Marketing Cloud, SQL and AMPscript, the overarching concepts for problem-solving can be applied to most
 Hi, Remember Me?
Hi, Remember Me?
Let’s recap. In Part 1 of Data Investigations, I introduced my enigmatic alter ego, Dr. Frankendata. My real name is Christopher Kayser and I’m a Sr. Solutions Architect at Response Labs. Colleagues dubbed the work I do with data and SQL, mad science. It’s true, my personality is maniacal when it comes to solving data problems. So I decided to channel the mania into advice that saves you time, trouble, and looming madness. 😵💫
My Top 5 Best Practices for Data Investigations
Data investigations range in complexity from a single personalized field not working in an email to an entire data processing automation screeching to a halt. Most data issues can be resolved by going through a few best practices. My process follows a step-by-step checklist:
- Follow the data backward, and then forward.
- Find the break.
- Try turning it off and back on.
- Consider breaking it into multiple steps.
- Break it yourself and rebuild it.
At face value, these practices are simple enough but the details are a bit more complex. In this post, I’ll cover the first of these best practices.
Now then, let’s get on with the investigation…
Best Practice 1:
Follow the data backward, then forward.
Let’s say you’ve got an email that isn’t pulling personalization data. For the sake of this example, it’s the first name that doesn’t show in the greeting. We’ll start our investigation by backtracking to identify the last point in time when the data populated.
In Salesforce Marketing Cloud, open your audience data extension and check if the first name is a populated field (and then verify that it is populated correctly). Or, if you are using system attributes for the customer, make sure that the customer’s profile actually has a first name (and that the variable in your data set matches the one you are trying to use in the email). If it’s a series of SQL queries or other data manipulation processes, go through a sample of each data set until you can find where the data was last behaving correctly.
This can be exponentially harder for processes you’ve inherited or that someone else built. So take notes and document the path that the data flows through. Go until you find the break. Don’t stop there. Continue following the process backward to make sure that the data actually is doing what it is supposed to at each step before the break. Just because you find a break in the chain, doesn’t mean there aren’t other ones leading up to that point.
Next, do the reverse. Start at the earliest ingestion point you can find in the data processing. Then follow three to ten records. If the issue happens where some records work and others don’t, you’ll want to investigate more records. Try to identify some records that do behave as expected and compare them to records that are not working. Follow the data flow to find where things veer off. Again, take notes.
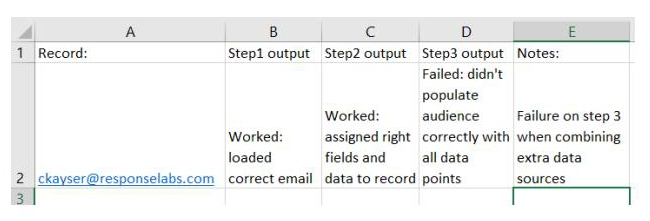
My go-to is an excel sheet where I can put the record’s identifying data points; an email address, unique id, or similar, and then mark how they progress and change through the flow.
You can flesh out your notes more with more details in each step if you’d like. For the first pass, I like to note what works and what doesn’t. I find that’s sufficient to identify where to focus my attention.
Following the data in AMPscript (or in-email scripting)
Now, let’s use the same first name personalization example to follow data in an AMPscript block. First, in the email itself, we have a variable called “Greeting” that pulls in either a “Thank you!” or “Thank you, (firstname)!” with the customer’s first name being populated as shown below:
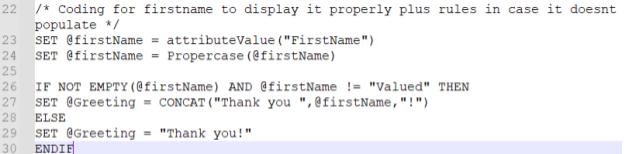
But let’s say that the “firstname” field here isn’t populating for some records. The first thing to do is to go into the code and see how the variable we have in the email copy for @Greeting is getting populated. In this case, we would see that lines 27 and 29 are in charge of setting @Greeting. We also see that line 26 is doing a check to see if the firstName is not empty and does not match the word “Valued.” Also, notice that on lines 26 and 27, the variable for first name is firstName with lowercase “f” and uppercase “N”. If we follow the logic backward, we then go to lines 23 and 24. Line 24 is setting the variable of firstName as the value of itself, but with the value being altered to be in the proper case, which means that the first name will be capitalized. In line 23 we see that the variable of firstName is being created and assigned the value of a system attribute called FirstName. Meaning we’re relying on the SFMC contact model to have a value populating FirstName.
So we have two paths to explore here. First, take a couple of minutes to verify the chain of variable names match. Make sure the greeting is spelled the same in each instance it’s being called or assigned. Then check that “firstName” is spelled consistently on lines 27, 26, 24 and 23. Second, grab the subscriberkey/unique id of a record where firstname is not getting loaded correctly, then navigate to the subscriber model in SFMC and search for the record to make sure they actually have a value for first name.
The above process has helped solve a lot of data investigations that I’ve come across. An incorrect variable is the culprit for many a headache.
Following the data in SQL:
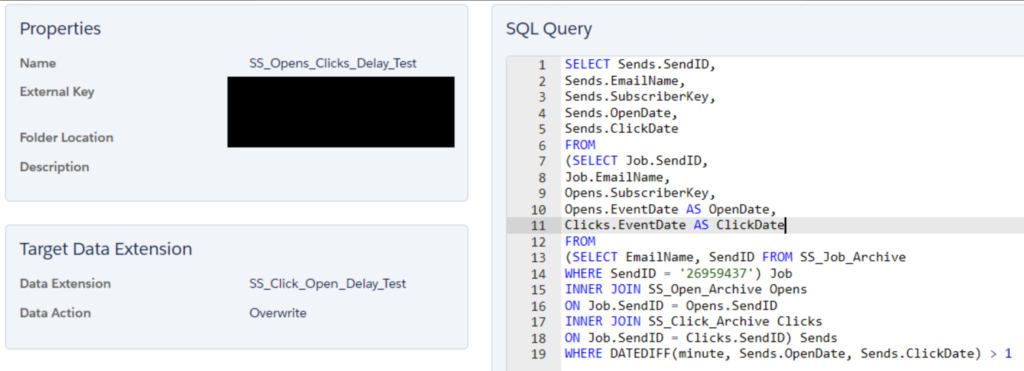
In the following example, we have a SQL with two tables being connected and a third table being used as a filter.
Check specific records.
If you have a specific record, navigate to the results and check the data there. Then, review the code to see if it makes sense why that record’s data looks the way it does. Go through the other tables that were pulled in and check what the data looks like in those records.
In the example, on lines 13-14, the query is outputting the email name and the numeric send identifier for that email where it matches to a known numeric send identifier. Lines 7-12 and 15-18 show that the query connects to other tables that pull information on an email’s SubscriberKey (sent, opened, and clicked). Here, we’d query each of those tables individually to make sure the specific record is actually on them. Depending on the account set up, you may be able to search the tables directly, or you may need to use query studio/SQL activity in order to query the tables directly. Either way, it’s still a good idea to follow the data and make sure it looks correct.
Take the opportunity to verify field names as well. Both SFMC and Responsys Interact have decent SQL interpreters that have rail guards on them that will normally let you know when a field name is misspelled or similar. But it’s never a bad idea to verify you have the right field names.
If you don’t have a specific record…
If it happens that you don’t have a record to focus on, gather a group of 10-50 records from one of the base tables used in your query. Copy and alter the query to only hunt for those 10-50 records. Either place the list of test records into another table using that as a base audience, or add a where the statement that has the list of records in it. Not necessarily best practice, but this is a way of testing and investigating queries.
To wrap up…
As a best practice, following the data helps you find the data issue and, at the same time, gives you an understanding of what data is being used and what’s happening to it. In my experience, this process typically helps solve most data investigations. Remember to take your time, take notes, and verify field names/variable names.
Keep an eye out for the next Data Investigations best practice, “Find the break.” I’ll dive into how to uncover breakage in data processes.
Until next time, thank you for your time and for indulging me to the end of this post.
